Unveiling the Concept of Information Entropy
This article aims to demystify information entropy, delve into its mathematical underpinnings, explore its practical applications across various fields, and highlight its significance in modern-day technologies.
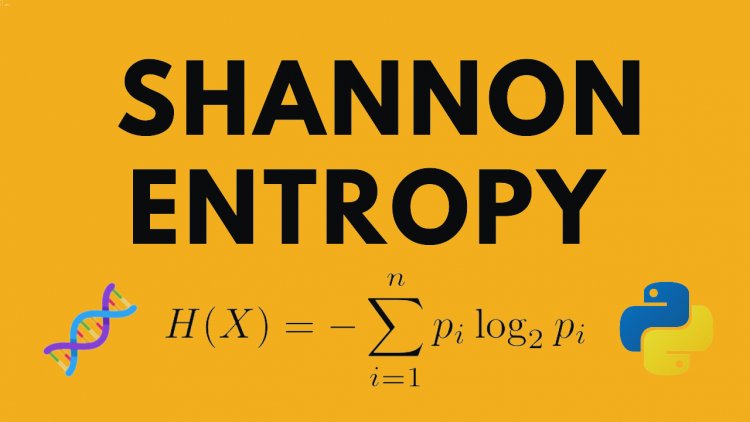
Understanding the Science Behind Data Disorder:
In the vast realm of information theory, one concept that stands out as a fundamental measure of uncertainty and disorder is "information entropy." Developed by Claude Shannon in the mid-20th century, it provides valuable insights into the structure, organization, and predictability of data. Whether you're a computer scientist, a data analyst, or simply a curious mind, understanding the concept of it is crucial in comprehending the intricacies of data and its representation. This article aims to demystify information entropy, delve into its mathematical underpinnings, explore its practical applications across various fields, and highlight its significance in modern-day technologies.
The Foundation of Information Entropy:
It serves as a measure of the uncertainty or randomness within a set of data. It quantifies the average amount of information needed to describe an event or the amount of surprise associated with it. At its core, it is closely related to the concept of probability. When the probability of an event is high, it is low, indicating higher predictability. Conversely, when the probability is low, it is high, indicating greater uncertainty.
The Mathematics of Information Entropy:
Mathematically, it is defined using Shannon's entropy formula: H(X) = -ΣP(x)log2P(x), where P(x) represents the probability of each possible outcome, and the sum extends over all possible outcomes. The logarithm in the equation reflects the logarithmic nature of information measurement.
This formula provides a means to calculate the entropy of discrete probability distributions. In the case of continuous probability distributions, the formula is modified accordingly. It's important to note that the unit of measurement for information entropy is bits. One bit represents the amount of information required to resolve a binary choice, such as a yes or no question.
Applications of Information Entropy:
It finds applications in various fields, including computer science, data compression, cryptography, and machine learning. In data compression, entropy coding techniques like Huffman coding and arithmetic coding leverage it to achieve optimal compression ratios by assigning shorter codes to more frequent symbols and longer codes to less frequent symbols.
In cryptography, it plays a crucial role in generating secure cryptographic keys. Randomness extracted from high-entropy sources helps ensure the unpredictability of cryptographic algorithms, making it extremely difficult for adversaries to decipher encrypted messages.
Furthermore, it aids in feature selection and dimensionality reduction in machine learning. By measuring the information gain or reduction in uncertainty, entropy-based criteria like decision trees and random forests can determine the most informative features for classification tasks.
Practical Implications and Challenges:
While it provides valuable insights, it also poses challenges in practice. One challenge lies in estimating the true entropy of complex systems or continuous variables, where precise probabilities are difficult to determine. Approximations and sampling techniques are often employed to tackle this issue.
Another consideration is the influence of bias and context in its calculations. The same set of data may yield different entropic values based on the chosen context or reference point. It's crucial to carefully define the scope and context of the data under analysis to obtain meaningful entropy measurements.
Conclusion:
In conclusion, it serves as a vital tool for quantifying uncertainty and disorder within data. By understanding its mathematical foundations and practical applications, we can harness its power to extract meaningful insights, enhance data compression techniques, strengthen cryptographic systems, and optimize machine learning algorithms.
As we continue to generate and process massive amounts of data in our increasingly interconnected world, it will remain a key concept in ensuring efficient data management, secure communication, and improved decision-making. Embracing the science behind data disorder will undoubtedly empower us to navigate the complexities of information theory and unravel the hidden patterns within our data-driven universe.














